
There was a fair amount of interest in my Carrot2 post, so this is a bit of a follow up. In short: it works on big datasets! On a trial collection of 1,023,042 URLs/documents, ingested from a large collection of websites, Solr indexed it in an hour and forty minutes. Carrot2 is working swimmingly (I increased memory in ~/solr/carrot2-workbench-3.7.1/carrot2-workbench.app/Contents/MacOS/carrot2-workbench.ini to approximately 7gb) and generates clusters from search queries.
In the first little bit that I’ve been playing with it, I’ve been impressed. To me, this really reinforces that I think this is a key tool that digital humanists might want to consider (and hopefully some people looking for similar tools stumble upon this blog post).
To give you a sense of how it works in practice, here’s a set of visualizations for the simple query history.

We’ve got some great results: we can see the interest in family history, individual nationalities (American and Irish), the links to research and educational life (students), and other things in the top 100 results that I’ve pulled as a trial. “Links” appear as a topic, perhaps indicative of the development of a community linked to each other.
If we scale it up to 10,000 results we’re getting even more information, but still some distortions.
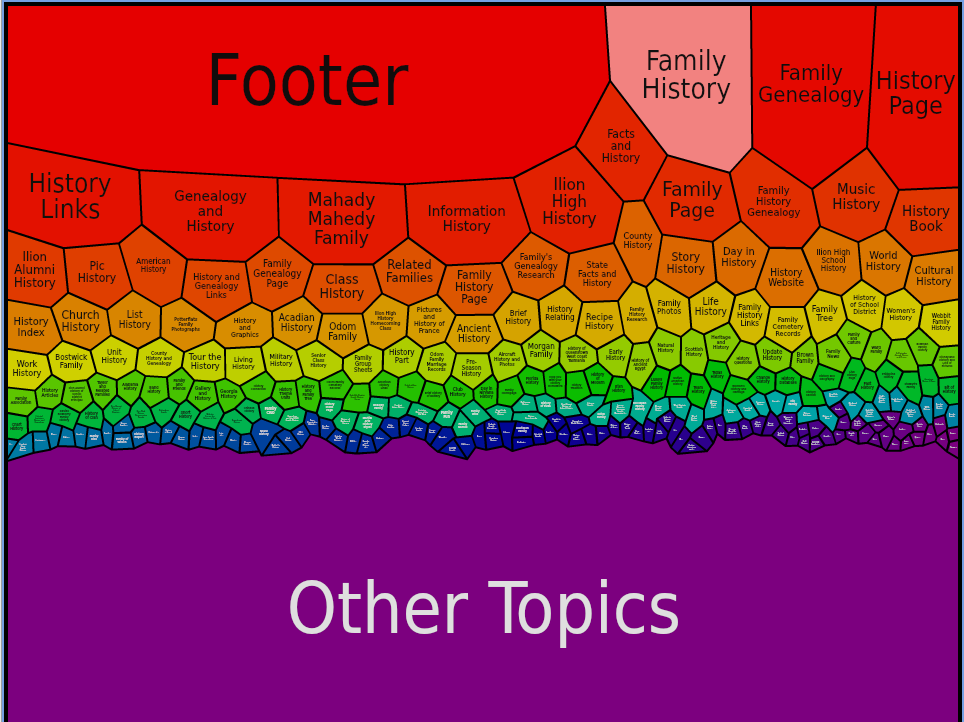
It’s diverse, it’s picking up common separate ‘footer’ pages across the collection and clustering them, but we’ve got some gems: again, family history is key, but so are distinct themes: “This Day in History” appearing across many websites, little Factoids and stuff, lists, food, but then descending into individual topics, from American, to Church, to French, etc.
Anyways, it’s all early days and this has only been running for an hour or so.

3 thoughts on “It Works! Cluster Results from a Million-Document Database”