
This is the first part in a series dealing with Internet Archive WARC files. This introduces the issue. The second introduces WARC Tools, and the third moves from that into a discussion of how to create a full-text searchable database.
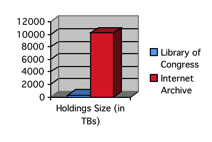
I’ve been doing a bit of work lately (in between my relocation to Waterloo, end-of-term marking, and general busyness) playing with WARC files. These files are, in a nutshell, a bundle of “multiple digital resources into an aggregate archival file together with related information.” It’s my belief that historians will be finding themselves increasingly using these files. The Internet Archive is a massive repository, as seen at right, and we’ll increasingly have to work with these files as we move into more and more recent histories. Archivists and librarians are well ahead of the curve on this, but rather than going to them with absolutely no knowledge I’ve endeavoured to learn a bit myself – that way my use of their limited time can be a bit more effective!
Yet these sources present both a boon and a challenge to historians. If the norm until the digital era was to have human information vanish, “[n]ow expectations have inverted. Everything may be recorded and preserved, at least potentially.” (Gleick, 2011) Useful historical information is being preserved at a rate that is accelerating with every passing day.
So what can we do? The main way to access WARC files is through the WayBackMachine. While most of us are familiar with the WayBackMachine as the primary way to access the Internet Archive’s web collection, it is also open source software that you can download and run as a local server on your personal computer. This is a tricky install, however, and requires a fair amount of playing around and being, honestly, frustrated. At some point when I get it stable I’ll share something here.
In the meantime, I’ve been creating test WARC files using wget (my Programming Historian 2 lesson is here). The newer versions of wget have WARC compatibility built in (earlier versions do not, however, so you’ll have to reinstall and compile wget if you’re on OS X). For example, to make a WARC file of this website, the following command would suffice:
wget http://ianmilligan.ca/ --mirror --warc-file="im"
Then you’d get a file in the directory you’re running it from labelled “im.warc.gz.” Decompress it, and you’ve just got the WARC file.
The trick then as a historian is what do you do with this sort of file? One thought I have is to load it into Mathematica. In lieu of a textual display, I thought one thing would be to quickly load up word clouds of each WARC file (code for this came from the always incredible Mathematica StackExchange). This involves doing a quick count of the files, taking the top 100, and arranging them a bit artfully to get a snapshot of the site. My code still needs refinement, as it’s cutting off both sides of the frequent “ianmilligan” word but we can begin to see some potential.

I know word clouds have their issues and caution, but as a useful icon inwards we can almost immediately see what the WARC file might contain. As a next step, we could start getting keyword in context together, which produces something like this:
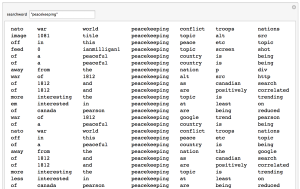
My goal whenever I have some time is to keep playing with WARC files and figure out how we, as historians, can start harnessing the Internet Archive file format for our uses.

I was just wondering what you used to programmatically extract the text from the WARC files. Also, thanks for this post — a future (or present) where historians work with WARC files is an interesting one to me, and it also seems to point to the opportunity for new & improved tooling (like wget) around WARC.
Glad to hear that you liked the post – I’m increasingly thinking that WARC has the potential to be the archive box of the future.
As for text, as you noted on Twitter, the mandalweb tools use Lynx to handle the text. In this first example, however, Mathematica can actually extract the text natively – it just takes a very long time (as opposed to the mandalweb process, which is extremely quick).