
 At the same time as I was in Denmark presenting at the National Webs workshop, my co-authors and University of Toronto collaborators Emily Maemura and Christoph Becker were presenting a paper we wrote at the IEEE Big Data Computational Archival Science Workshop. This is the first fruits of the McLuhan Fellowship I’m doing at the University of Toronto, and introduces a model for using Research Objects with web archival research.
At the same time as I was in Denmark presenting at the National Webs workshop, my co-authors and University of Toronto collaborators Emily Maemura and Christoph Becker were presenting a paper we wrote at the IEEE Big Data Computational Archival Science Workshop. This is the first fruits of the McLuhan Fellowship I’m doing at the University of Toronto, and introduces a model for using Research Objects with web archival research.
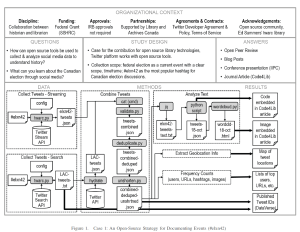
Abstract is below, and you can find the full pre-print here.
Use of computational methods for exploration and analysis of web archives sources is emerging in new disciplines such as digital humanities. This raises urgent questions about how such research projects process web archival material using computational methods to construct their findings. This paper aims to enable web archives scholars to document their practices systematically to improve the transparency of their methods. We adopt the Research Object framework to characterize three case studies that use computational methods to analyze web archives within digital history research. We then discuss how the framework can support the characterization of research methods and serve as a basis for discussions of methods and issues such as reuse and provenance. The results suggest that the framework provides an effective conceptual perspective to describe and analyze the computational methods used in web archive research on a high level and make transparent the choices made in the process. The documentation of the research process contributes to a better understanding of the findings and their provenance, and the possible reuse of data, methods, and workflows.
